Abstract
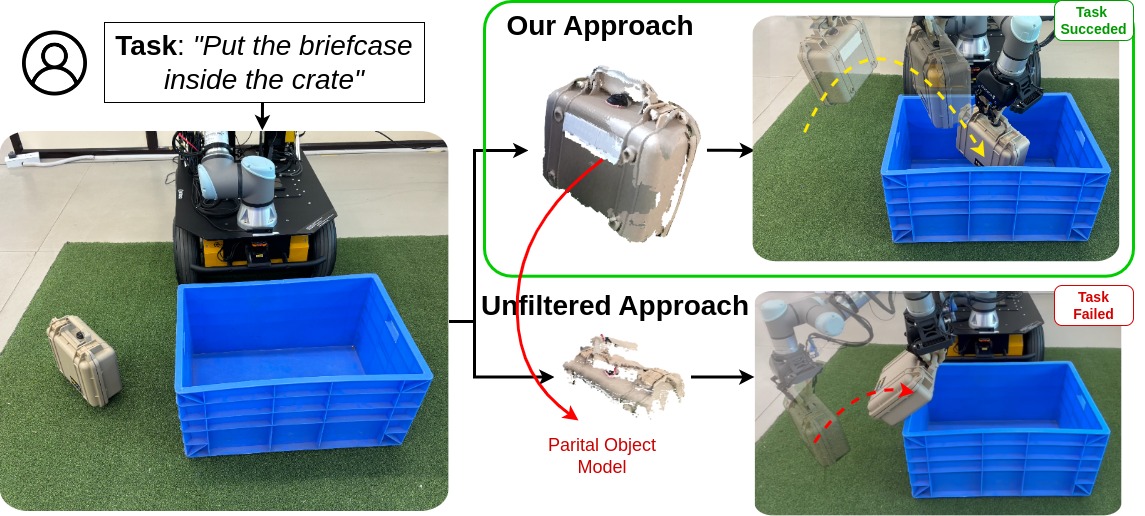
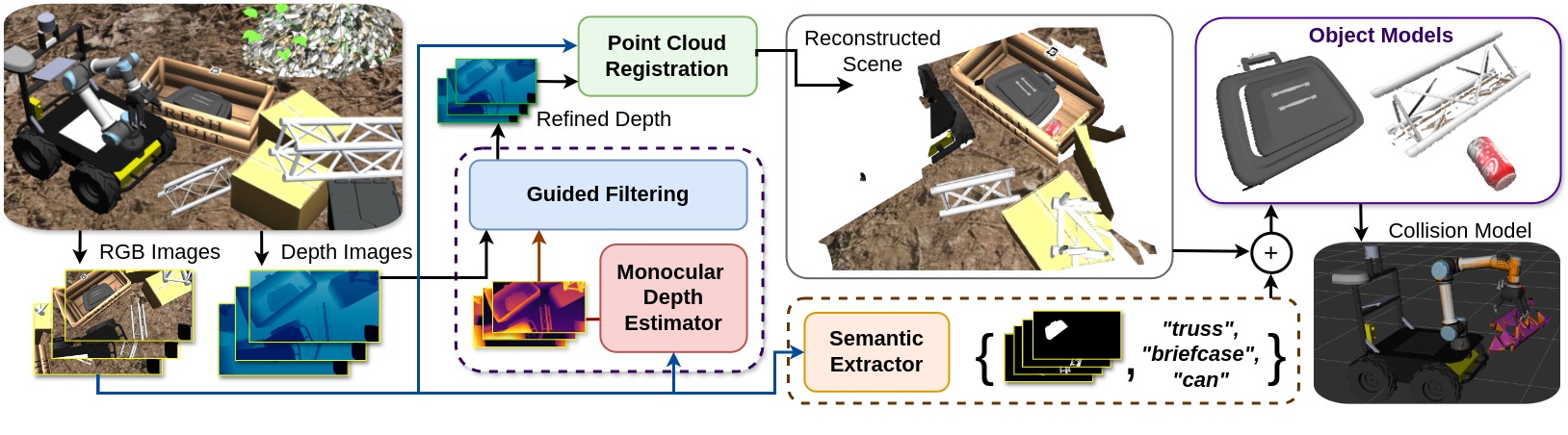
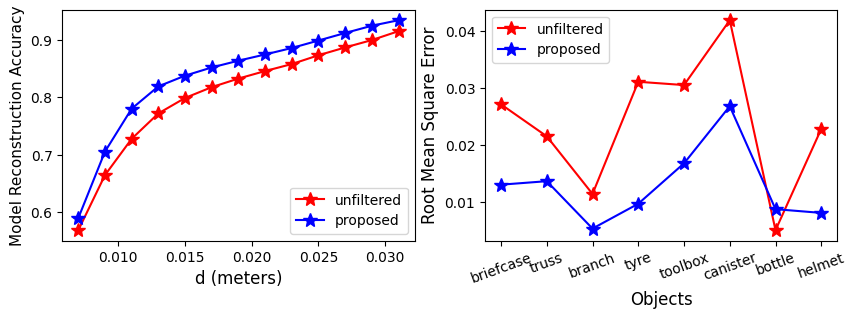
This paper addresses the challenge of acquiring object models to facilitate task execution in unstructured, unknown environments. Illustrated through the scenario of commanding a robot to explore unfamiliar terrain and interact with objects, the necessity of a metric-semantic representation of the environment becomes apparent. Such representation not only identifies present objects but also maintains their geometric attributes for future interactions, such as manipulation or relocation. Handling large, unfamiliar objects, like trusses or tree branches, necessitates intricate reasoning in grasping, transport, and placement phases, posing a significant challenge for a versatile manipulation agent. The paper proposes an approach that integrates prior knowledge from pre-trained models with real-time data to generate detailed object models, essential for sequential manipulation tasks. This method involves utilizing pre-trained Vision-and-Language Models (VLMs) to extract object masks from raw point clouds and integrating depth priors from foundation models for improved geometric accuracy. Furthermore, the approach includes mechanisms for building local maps and local repairs over sequential action execution. Experimental results demonstrate the effectiveness of the proposed approach in acquiring high-quality 3D object models compared to alternative methods for unstructured scenarios.